Efficient modular architectures for speech and natural language processing
PhD - Gent | More than two weeks ago
Background:
Recent AI systems such as ChatGPT and Whisper have posted impressive results on tasks that were once regarded as the cornerstones of human intelligence, namely speech and language processing. However, to achieve these results, those systems need to be trained on far more data than any human has ever read or listened to, exceeding even what 100 humans can process in their combined lifespans. This indicates a clear gap in the learning capabilities of the current generation of AI systems and that of humans. And while the massive amounts of data on the Internet can masks these learning deficiencies for common languages such as English and Chinese, other languages such as Dutch or French, especially given their large variability due to e.g. dialects, are in a less desirable position.
Previous generation AI systems did manage to obtain good performance with far less data by relying on human expertise, who decomposed the problem into smaller sub-problems by introducing intermediate concepts such as phones, morphology, syntax, word ontologies, etc. This PhD aims to develop methods to integrate existing human knowledge efficiently in modern speech and language AI architectures, and to develop techniques such that AI systems can automatically decompose (e.g. factorize) problems into smaller sub-problems, hence making it possible to generalize better given finite amounts of training data. Making the AI systems more modular also has the potential to reduce the computational and memory load of modern AI, making future systems more hardware-efficient and less energy hungry. The work will therefore also take software/hardware co-design in consideration, thus having a direct link with the ongoing methodological developments in that domain at imec and providing a challenging use case for those developments at imec.
Research Objectives:
This research will focus on the following key objectives:
1. Modular deep learning architectures: The current big AI models all have a rather uniform design: just multiple layers of transformers or conformers. Bringing in existing knowledge on intermediate levels (phonemes, morphology, etc.) will require novel architectures, where sub-components can even work on different time scales, i.e. different from the current fixed scale time subsampling.
2. Graph-based uncertainty propagation: Current big AI models pass information through layers using a large but fixed sized embedding. In complex AI systems such as LLMs or speech recognizers, these embedding must encode multiple hypotheses (e.g. continuations of a story) in combination with a probability distribution over these multiple hypotheses. Using a fixed size vector for this purpose is inefficient and limiting. Graphs (lattices) provide a far more elegant solution to represent multiple hypotheses with their underlying uncertainties. Note that refactoring deep learning architectures to work with graphs, while being mindful of the constraints of hardware platforms, is a highly challenging task, but one that can bring huge merits to future AI platforms. Explicit modelling of alternatives and probabilities also provides a solid starting point for tasks where humans and AI interact to co-optimize that task, or where multiple AI agents collaborate on a task.
3. Automatic factorization algorithms: Current big AI models use tokens to represent classes. However, many problems require far more classes (e.g. there are over 6 million wordforms in Dutch) than can be coped with in neural networks. The current byte pair encoding (BPE) for text provides a solution, but this solution is based on character co-occurrences only, resulting in tokens that are not overly correlated with word meanings of pronunciations, making the task of all subsequent layers more challenging. Representing words with multiple informative tags, similar to multi-head reasoning, is expected to make the reasoning in the subsequent layers easier. This work is expected to result in novel algorithms/architectures that allow deep neural networks to handle joint labels and the resulting joint (or conditional) probabilities.
4. Prototyping and Validation: Build a prototype speech interface for Flemish. This will allow the evaluation of the efficacy of the new AI algorithms, both in terms of accuracy and hardware-efficiency. Moreover, such a task would form an excellent case for the validation of other AI methodologies and hardware developed at imec.
Significance:
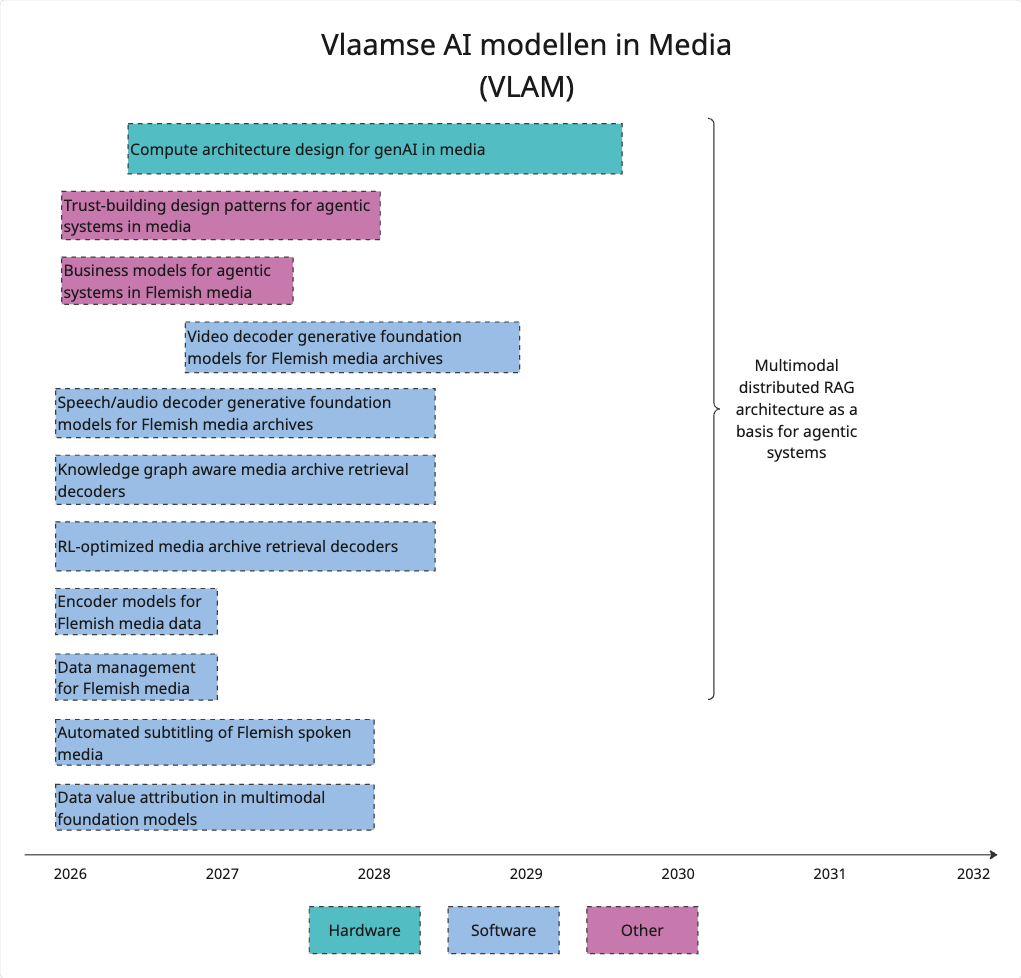
The work fits into the new VLAM (Vlaamse AI modellen in Media) roadmap, more specific under the “Speech/audio decoder generative foundation models for Flemish media archives” chapter. This work will help in understanding how the disruption of agentic AI will impact the media companies, and will help in creating future multi-modal interfaces with excellent support for speech and language based interaction which is still the primary way humans convey information.
This research is also expected to significantly improve speech and language technology for languages such as Dutch (Flemish), i.e. languages with limited audio availability (compared to English) but with a good computer linguistic underpinning. These requirements hold for most European languages, so the results are not limited to the Flemish language.
Moreover, the more modular approach is expected to reduce the computational load of speech and language models in general, thus making deployment of these techniques more manageable and more economically viable.
Finally, the basic techniques (factorization, decomposing problems, graph-based DNN techniques) are of use to many deep learning problems, and hence this project could help in fueling the next leap in AI.
Requirements:
Our ideal candidate for this position has the following skills:
You have a master’s degree in computer or electrical engineering or equivalent
Knowledge related to modern speech and language processing techniques is a plus
Knowledge in deep learning is a plus
Knowledge of estimating algorithmic complexities (what is feasible, how can this be done efficiently on existing hardware) is a plus
You have experience programming in Python.
You can plan and carry out your tasks in an independent way.
You have strong analytical skills to interpret the obtained research results.
You are a responsible, communicative and flexible person.
You are a team player.
Your English is fluent, both in speaking and writing
Required background: computer or electrical engineering, preferably with notions of deep learning
Type of work: 20% literature, 70% modeling/system design, 10% evaluation
Supervisor: Kris Demuynck
Co-supervisor: Tanguy Coenen
Daily advisor: Jenthe Thienpondt, Kris Demuynck
The reference code for this position is 2026-030. Mention this reference code on your application form.