Designing and Compressing Deep Learning Models for Edge Computing Devices
Gent | More than two weeks ago
investigate approaches to jointly optimize the architecture and mapping of deep neural networks onto edge devices
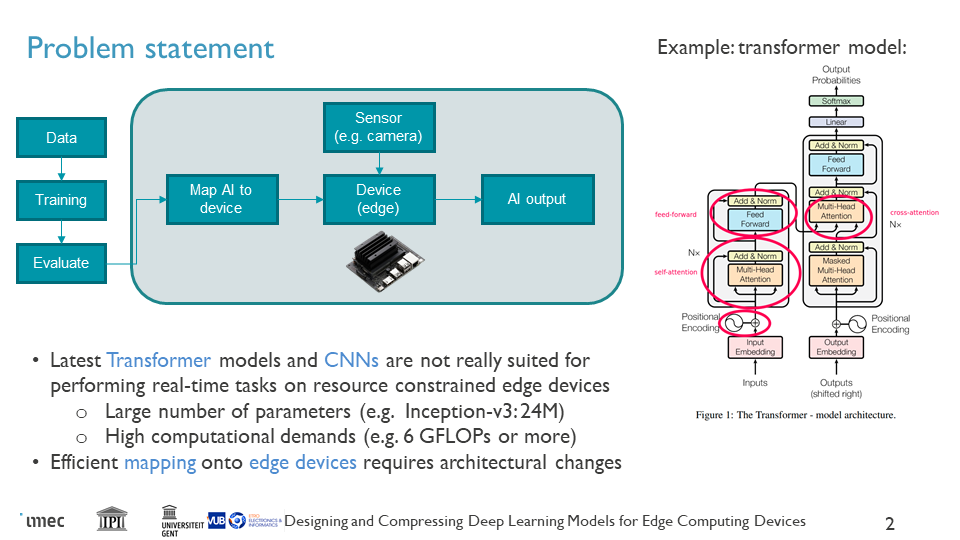
Deep machine learning models have achieved state-of-the-art performance in most image processing (e.g., super-resolution, denoising, reconstruction) and computer vision tasks (e.g., classification, se- mantic segmentation, and object detection). Powerful deep learning modes (e.g., Transformers, deep Convolutional Neural Networks) are not suitable for performing such tasks on resource-constrained, mobile devices because they contain a large number of parameters and require a substantial amount of floating point operations (FLOPs); for instance, Inception-v3 has approximately 24M parameters and requires 6 GFLOPs to process an image with a spatial size of 299 × 299 pixels. Various studies have focused on compressing pretrained models by means of quantization, pruning, or knowledge distillation; however, these methods are only partially successful: improvements in computational performance are often obtained at the cost of a severely reduced numerical accuracy.
This PhD study will follow an innovative approach focusing on (i) model aware machine learning, which refers to the design of efficient neural networks that capture prior knowledge about the data and task at hand and thereby leading to substantially smaller models with state-of-the-art or superior performance compared to their deep counterparts; (ii) combining classical machine learning algorithms with deep neural networks, where the programmed parts of the algorithms implement differentiable functions optimized along with the weights of the neural network; (iii) designing novel cost functions (e.g., based on sparse coding) and optimization strategies for the training of the mobile models.
We are looking for a motivated Ph.D. candidate who is interested in bridging the gap between image processing and AI accelerator hardware. New techniques will be studied to reduce the computational complexity/memory demands of a deep neural network, by allowing architectural modifications such as inclusion of classical (differentiable or non-differentiable) image processing techniques, algorithmic unrolling, and learning-to-optimize (L20) approaches. In this process, you will learn about various hardware mapping and optimization techniques developed at imec and will create mapping tools for novel hardware compute architectures at imec.
Required background: Master of Science in Computer Science, Master of Science in Appied Mathematics or equivalent
Type of work: 30% modeling, 30% programming, 30% experimental, 10% literature
Supervisor: Bart Goossens
Co-supervisor: Nikolaos Deligiannis
Daily advisor: Debjyoti Bhattacharjee
The reference code for this position is 2024-034. Mention this reference code on your application form.