
DRAM (or dynamic random access memory) is predominantly used as the computer’s main memory – the memory from which the central processing unit (or CPU) reads its instructions. Through the years, different DRAM standards have emerged, serving different needs and applications. Each standard has been further developed into different generations in order to answer the need for ever increasing bandwidth. In this article, Timon Evenblij, system memory architect at imec, and Gouri Sankar Kar, program director at imec, review different DRAM flavors and identify common trends and bottlenecks. They also propose the routes that imec follows in order to push DRAM performance to its ultimate limits.
DRAM: the basics
Bit cell
Before diving into different DRAM flavors, let’s start with the basics – based on a lecture from prof. O. Mutlu.
Any memory is built up using bit cells, which is the semiconductor structure that stores exactly 1 bit, hence its name. For DRAM memories, the bit cell consists of a capacitor and a transistor. The capacitor is used to store a charge, and the transistor is used to access the capacitor, either to read how much charge is stored or to store a new charge. The wordline is always connected to the transistor gate, controlling the access to the capacitor. The bitline is connected to the source of the transistor, reading the charge stored in the cell or providing the voltage when writing a new value to the cell. This basic structure is very simple and small, so manufacturers can process a very large amount of them on a die. One disadvantage is that the single transistor is not very good at keeping the charge in the small capacitor. It will leak current from or to the capacitor, making it lose its well-defined charge state over time. This problem is circumvented by periodically refreshing DRAM memories, which means reading the content of the memory and writing it back. Attentive readers might have noticed that when a charge is read from the capacitor, it is gone. After reading a value from a DRAM cell, the value should be written again. This is what gives the name ‘dynamic’ to DRAM.

DRAM bit cell
Do you want regular updates on imec’s semiconductor research?
Accessing arrays of bit cells
Many cells can be combined into large matrix-like structures. Long wordlines and bitlines cross each other and a bit cell is processed at each intersection. Putting a voltage on a wordline selects all corresponding cells, which will put their charge on their respective bitlines. This charge will change the voltage of each bitline very slightly. This slight change is detected using sense amplifiers, structures who will amplify a small positive change in the voltage to a high voltage (representing a logical 1), and a small negative change in the voltage to zero voltage (representing a logical 0). The sense amplifiers store the logical values into a structure of latches, called the row buffer. The row buffer acts like a cache holding the values just read from a single word line worth of bit cells, since the values are lost in the cells when they are read. The process of sensing is an inherently slow process, and the smaller the capacitors and the longer the bitlines, the longer this process takes. This sensing time is what dominates DRAM access times, and it has remained about the same value in the last decades. The ever-increasing available bandwidth for each DRAM generation is enabled by exploiting more parallelism in DRAM chips, rather than decreasing the cell access time. But before going deeper into this issue, let’s take a look at how a memory system is built using a lot of these bit cells. The architecture described here is for typical desktop systems using memory modules. For other DRAM flavors, the concept of a module is not used, but most of the architecture can be described with the same terminology.
DRAM architecture
On the processor, there is some part of the logic dedicated for a memory controller. This logic handles all accesses from the CPU to the main memory. Processors can have multiple memory controllers. Memory controllers have 1 or more memory channels. Each memory channel consists of a command/address bus and a data bus (which is 64 bits wide in the default case). To this channel, we can connect 1 or more memory modules. Each memory module consists of 1 or 2 ranks. A rank contains a number of DRAM chips that combined provide enough bits each cycle to fill the data bus. In the regular case where the data bus is 64 bits wide, and each chip provides 8 bits (so-called x8 chips), a rank would contain 8 chips. If there is more than 1 rank, the ranks are multiplexed on the same bus, so they cannot put data on the bus at the same time. The chips per rank operate in lockstep, which means they always execute the exact same commands and cannot be addressed separately. This is important for the following: each chip consists of several memory banks, which are the large matrices of bit cells with word lines, bit lines, a sense amplifier and row buffer, as introduced earlier. Since chips in a rank operate in lockstep, the term memory bank can also refer to the 8 banks across the 8 chips of the same rank. In the first case we might use the term physical bank, while in the latter case the term logical bank is preferred, but this terminology is not always clearly defined in literature.
With all the previous terminology, we are now able to talk about different DRAM flavors and generations, and how they improve upon each other. Again, let’s start first with regular DRAM modules for PCs.
DRAM standards
Regular DDR
DRAM memories already exist for a very long time, but we won’t give you a complete history lesson. We will go shortly go back to single data rate (SDR) memories, before jumping into double data rate (DDR) generations. What we need to know about SDR, is that the interface and data bus was clocked (IO clock) at the same frequency as the internal memory (internal clock). This kind of memories are limited by how fast the internal memory can be accessed.
The first DDR generation aimed at transferring two data words per every IO clock cycle, the first word on the rising edge of the clock and the other on the falling edge of the clock. The designers did this by introducing the concept of prefetching. A so-called prefetch buffer was inserted between the DRAM banks and the output circuitry. It is a small buffer that can store 2 times the number of bits that would be put on the bus each cycle in the original SDR design. In case of an x8 chip, the prefetch buffer would be 16 bits in size. We call this a 2n prefetch buffer. With a single internal read cycle of a complete DRAM row of e.g. 2k columns, there is more than enough data to fill this prefetch buffer. In this prefetch buffer, there is enough data to fill the bus with a word on both the edges of the clock.
The same prefetching idea was applied with DDR2, now with a prefetch buffer of 4n. This allows the designers to double the IO clock compared to the internal clock, and still fill the data bus every cycle with data. DDR3 takes the same idea further, again doubling the prefetch (8n), and the IO clock, now 4 times the internal memory clock.

Prefetching in DDR (Source: https://www.synopsys.com/designware-ip/technical-bulletin/ddr4-bank-groups.html)
However, there are limits to how far we can keep pushing the same idea. Doubling the prefetch buffer another time to 16n would mean that for each read command, 16 times 64 bits would be transferred towards the processor. This is twice the typical size of a cache line, the basic unit of data used in processor caches. If only 1 cache line would contain useful data, we would waste a lot of time and energy by transferring the second cache line. Thus, DDR4 did not double the prefetch, but applied another technique: bank grouping. This technique introduces multiple groups of banks, with each group having its own 8n prefetch buffer, with a multiplexer to select the output from the right group. If the memory requests from the controller are interleaved, so that they access different groups on successive requests, the IO speed can again be doubled, now 8 times the internal clock speed.

Bank grouping (Source: https://www.synopsys.com/designware-ip/technical-bulletin/ddr4-bank-groups.html)
So, what is next for DDR5, which also aims to double the IO speed? Well, DDR5 aims to borrow a technique already implemented in LPDDR4, which we call channel splitting. The 64bit bus is divided into 2 independent 32bit channels. Since each channel now only provides 32 bits, we can increase the prefetching to 16n, which will result in an access granularity of 64 bytes, which is exactly equal to the cache line size. The increase in prefetching allows again for a higher IO clock speed.
Of course, increasing the IO clock speed is not as easy as just having enough data available to fully use the bus in each cycle. Multiple challenges related to high frequency signals have presented themselves such as signal integrity, noise, and power use. These are solved by several techniques, such as on-die termination, differential clocking and general closer integration of memories with the processor. These techniques originate mostly from other DRAM flavors, namely LPDDR and GDDR, but I will focus more closely on integration.

LPDDR
LPDDR stands for low power double data rate. The main idea behind this standard is to lower the power usage of the memory, as the names implies. This is done in multiple ways.
The first distinction with regular memories is how the memory in connected with the processor. LPDDR memories are closely integrated with the processor, either soldered on the motherboard, close to the CPU, or increasingly common, provided as package-on-package directly on top of the processor (mostly an SoC in this case). Tighter integration allows for less resistance in long wires connecting the memory to the processor, resulting in lower power.
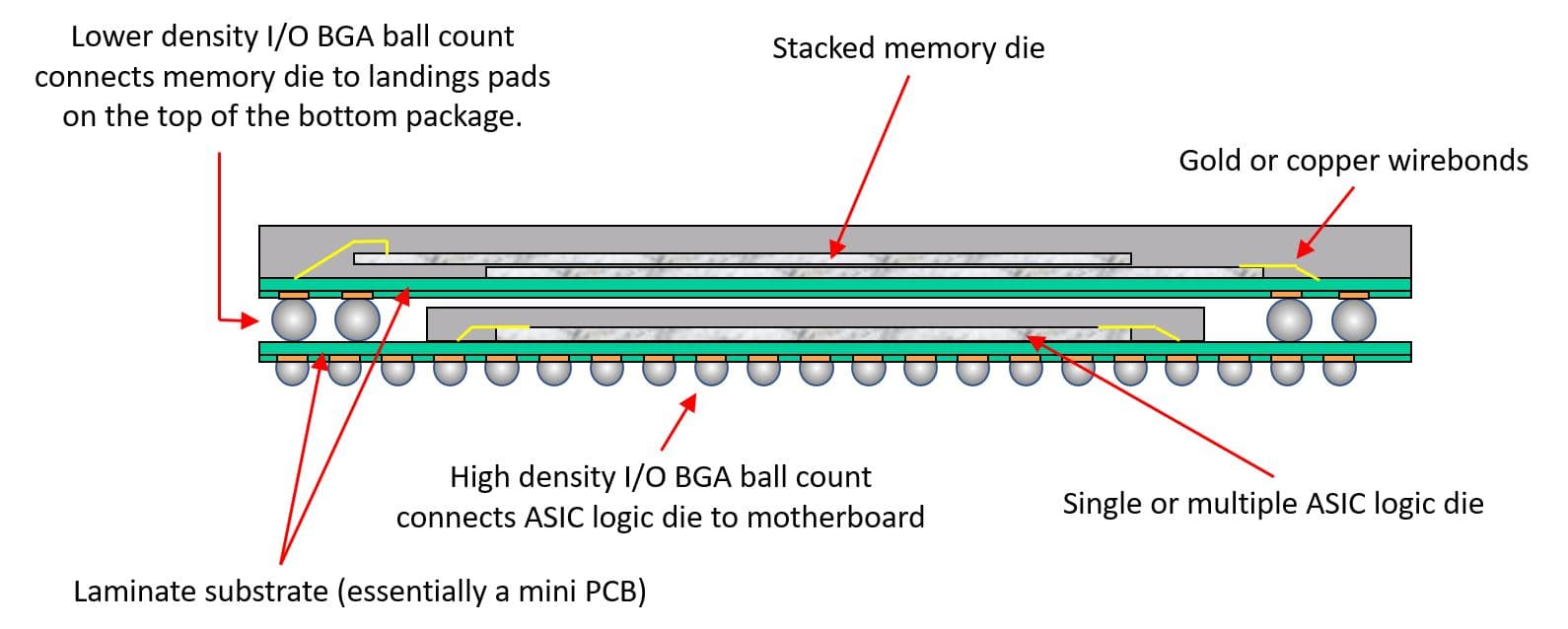
Package-on-Package integration (Source: https://upload.wikimedia.org/wikipedia/commons/0/08/ASIC_%2B_Memory_PoP_Schematic.JPG)
The second distinction is the channel width. LPDDR memories don’t have a fixed bus width, although 32-bit busses are most common. This is a smaller bus compared to regular memories, saving power. Also, a lower voltage is used in the memories, which also has a big impact on the power use. Finally, the standby power of memories is greatly reduced in LPDDR memories, by optimizing the refresh operation with various ideas, such as temperate adjusted refresh, partial array self-refresh, deep power-down states and more. We won’t dive deeper into these techniques right now, but generally they trade off some response time with a lower standby power usage, as the memory needs time to ‘wake up’ from a power saving more before being able to respond to the request.
The following table shows the generational changes in LPDDR memories, implementing the same techniques to improve performance, as discussed in the previous section. However, LPDDR4 was the first standard to introduce 16n prefetch and channel splitting, while LPDDR5 is expected to be the first LPDDR standard to introduce bank grouping.

GDDR
GDDR stands for graphics double data rate, implying the standard is for memories intended to be used in graphics cards. Nowadays, they are interesting for any application with a high bandwidth demand, as this is what they are focused on. GDDR memories are also pretty closely integrated with the processor, in this case the graphics processor, by being soldered on the PCB. These are not implemented on top of the GPU, as it would be hard to reach the desired capacity in this case, and because the generated heat would be hard to cool in this scenario. Each GDDR chip has a larger width compared to the typical DDR chip (e.g. 32 bit), and each chip is connected to the GPU directly, without being multiplexed on a fixed 64bit sized bus. This means having more GDDR chips on a graphics card means having a larger bus. Eliminating the multiplexing of connections also allows for higher frequencies on these connections, enabling an even higher IO clock frequency in GDDR memories. The higher IO clock speeds are enabled by higher internal read speeds, by using smaller memory arrays and bigger periphery, reducing the memory density of GDDR chips.
The tight integration means the final capacity of a graphics card is even more limited, since only 12 GDDR chips can fit closely around a large GPU.
Throughout the GDDR generations, the same techniques as in DDR are used to improve the memory bandwidth. The first GDDR standard was GDDR2, which was based on DDR. GDDR3 was based on DDR2. GDDR4 barely existed and can be skipped here. GDDR5 is based on DDR3, and was and still is very popular. It implements differential clocking and can keep two memory pages open at once. GDDR5X is a mid-generation performance enhancement for GDDR5, introducing a quad data rate (QDR) mode with 16n prefetching, at the cost of a larger access granularity, which is less of a problem for GPUs. GDDR6 then splits the channel, like LPDDR4. This provide 2 independent smaller channels on the same bus, enabling a smaller access granularity, making the 16n prefetch QDR mode standard. Yes, this means GDDR6 could probably be more aptly named GQDR6.

The 3D revolution
All things previously discussed happened without any of the 3D revolution. With 3D, we here refer to the use of trough-silicon-vias (TSVs) – which are vertical interconnects in the dies that can be connected using microbumps between the dies. Two dies put on top of each other can now potentially communicate with a lot of very small vertical interconnects. This enables completely new designs and architectures. Let’s look at the counterparts to the DRAM flavors discussed before. The most famous one is High Bandwidth Memory (HBM), which is the 3D counterpart to GDDR. Hybrid memory cube (HMC) was a proposed 3D counterpart intended for similar applications as general DDR, developed by Micron, but was cancelled in 2018. Wide I/O is a JEDEC standard pushed by Samsung for the 3D counterpart to LPDDR memories in SoCs, but I have not heard about real implementations yet.
HBM
HBM has a lot in common with GDDR. The memory chips are also integrated closely with the GPU. They are also not put on top of the GPU, since we still need a lot of capacity and we need to cool the chips. What is different then?
First, instead of putting the memory chips on the PCB close to the GPU, they are put on an interposer connecting the chips with the GPU. Today, typically a passive silicon interposer is used, which is a large silicon chip, but without any active components: it only has interconnects on it. The advantage of this interposer is that we can route a lot more parallel interconnects on it that don’t consume a ton of power. Hence, a very wide bus can be created, which was impossible on a PCB. This interposer, while fairly simple to create, still is a large piece of silicon, so it introduces a higher cost.
Secondly, memory chips can be stacked, enabling high capacities on a small area in the horizontal plane. These chips have a large amount of TSVs, connecting the chips in the stack with each other and the logic die at the bottom. This logic die is then again connected with the wide bus on the interposer, enabling the high bandwidth between memory chips and GPU. In fact, the bus is wide enough, that the IO clock of the memory chips can be relaxed to lower frequencies. This, together with the very short interconnects to the GPU, enables a much lower energy per bit (around 3x) when using HBM.


The following table shows some of the key specs of the HBM generations. Currently, HBM2 memories are available. Interestingly, Samsung recently announced HBM2e memory, where their chips go out of standard specification by having a larger capacity per die (16Gb) and increasing the data rate even more (410GB/s per stack).

HMC
Although Micron cancelled their efforts on the standard of HMC, we still want to give it at least a few words. HMC was the 3D counterpart to regular DDR memories, especially in future servers. This perception was not always clear in the industry. HBM really focusses on bandwidth, it needs to be closely integrated, trading off capacity and expandability. This is called a near memory. HMC focused on capacity and easily plugging in more memory stacks into a server, the same way more DDR memories can easily be plugged into a motherboard with free slots. It provided the loose integration required for high total system memory capacity. This is sometimes called far memory.

Next to this similarity, HMC is the standard that differs the most from DDR, more than any other standard mentioned in this article. Instead of using the DDR signaling across a bus, it uses memory packets, sent on high speed SerDes links between the processor and the memory cubes. This way, daisy chaining cubes is possible, enabling even higher capacities with limited interconnects. Also, a memory controller was completely integrated in the base die of each cube, instead of being on the CPU die as in DDR, or being spread over both the GPU and the memory stack, as in HBM.

Wide I/O
Wide I/O is the 3D counterpart to LPDDR memories, opting for extreme integration to reach the lowest power possible. The memories are expected to be integrated directly on top of SoCs, using TSVs to connect directly to the CPU die. This will enable extremely short interconnects, requiring the least power of any standard. Also, depending on the density and size of the TSV technology, very wide busses are also possible. However, this extreme integration will also require TSVs in the SoC, which consumes a lot of precious logic area, and thus is very costly. This is probably a big reason why we haven’t seen any commercial products yet with this technology. Perhaps interesting is that the first Wide I/O standard implemented an SDR interface, but the second-generation standard shifted to a DDR interface.
Different DRAM flavors: a recap
We have presented some of the intrinsic design trade-offs different DRAM flavors have made and will make in the future. In the end, each standard implemented the same ideas to improve the bandwidth in each generation, including techniques such as larger prefetch buffers, bank grouping, channel splitting, differential clocking, command bus optimizations and refresh optimizations. Each standard just has its own focus, whether it is a) capacity and flexible integration (DDR and HMC), b) the lowest power (LPDDR and Wide I/O), or c) the highest bandwidth (GDDR and HBM). It is interesting to see what 3D technology brings to this table, for each target market. The close 3D integration of memory is an effective way to improve bandwidth, but it is fundamentally limited in capacity. There is a limit in how much memory stacks you can put close to the compute units, there is a limit on how much memory dies you can put in a single stack, and as we’ll see, we are close to the limit on how much memory cells we can put on a single DRAM die. As applications require ever more data, the memory density becomes an ever more important dimension of the memory wall.
Further outlook: an imec view
Imec explores two possible paths to push DRAM technology to its ultimate limit, to help tackle the memory wall. Using fundamentally different technologies, these exploration paths will call for new architecture standards to enable the next era of DRAM memory.
The first path is to improve the dynamic nature of the DRAM bit cells. As explained in the introduction, the charge stored in the capacitor of a DRAM bit cell slowly leaks away. Therefore, DRAM memory needs to be refreshed. Each row is typically refreshed in 64ms. This incurs an overhead, both in power and in performance. Ferro capacitors are a promising way to let DRAM bit cells store their charge for longer periods, which also helps to ease the stringent requirement of select transistor off current. They could improve the retention time of the DRAM memory – which introduces many benefits, such as negligible refresh overhead, fast switching to and from power down modes, lower standby power – as well as push the DRAM scaling further. Within its ferroelectric program, imec is developing ferroelectric based metal-insulator-metal (MIM) capacitors to explore this path. A new DRAM architecture standard focusing on these non-volatile-like properties will be required to exploit this technology effectively for the lowest power.
The above-mentioned path may not be best option to continue the DRAM scaling roadmap for many more generations. Due to scaling issues, the die density has started to saturate around 8-16GB – making it hard to make DRAM chips with capacities larger than 32GB. If we want to follow the scaling path, even more disruptive innovations will be needed. One option is to replace the Si-based transistor within the DRAM cell with a transistor made from low leakage deposited semiconductor thin-film transistor (TFT), such as indium-gallium-zinc-oxide (IGZO). The high bandgap of this material ensures a low off-current – a characteristic that is mandatory for a DRAM cell transistor. Since we do not need Si anymore to make the cell transistor, we can now move the periphery of the DRAM cell under the DRAM array. This way, the footprint of the memory cell can be significantly reduced.
In a next step, we are looking at stacking of DRAM cells. The capacitor – which is needed to store the charge – has reached its scaling limits. But what if we could store the charge by using a very small capacitor or even no capacitor at all? The very low leakage current of the IGZO transistor may open a possible path towards building a capacitor-less DRAM cell. Even more, as there is no capacitor anymore and the materials used for the IGZO transistor are compatible with processing in the back-end-of-line, opportunities exist to build these bit cells on top of each other in a vertical way with a scalable process. This brings many benefits, but also many challenges across different abstraction layers such as process, technology, bit cell design, memory circuit design, and system architecture. Imec is looking at potential cross-layer solutions to solve these challenges in a future high-performance DRAM standard that may offer a way to scale DRAM memories far beyond currently assumed limits.
Part of this article originally appeared in Semiconductor Digest, February 2020.













{kind=link}