
Best of 2016 / Edition November 2016
Transistor scaling has brought us a lot of benefits, but also a myriad of reliability issues. To extend the scaling path as far as possible, system architects and technologists have to work together. They have to find solutions – e.g. at system level – to realize self-healing chips, chips that can detect or ‘feel’ where errors occur and that know how to deal with them or in a way ‘cure’ them. Only then will it be feasible to design systems in technologies with transistors scaled down to 5nm dimensions. Two specialists in the field explain how to make such self-healing chips: ‘system architect’ Francky Catthoor and ‘technologist’ Guido Groeseneken.
Until a few years ago, manufacturers of ICs in less-deeply scaled CMOS technology could sell electronics with a guaranteed lifetime. The chips inside were built with devices that all had the same average characteristics and would all age in a predictable way. A so-called guard-band approach guaranteed proper functioning of the circuits and chips: extra margins were added to the average characteristics of the transistors to ensure good functioning, also in extreme scenarios. Due to scaling and related reliability issues, these margins or guard bands have risen from 10% to much higher ranges. As a result, from 14nm on, the guard-band approach will become gradually untenable for systems that require some type of guarantees. Does this mean the premature end of scaling?
Making reliable systems with unreliable devices
Groeseneken: “Maybe it means the end of the guard-band approach, but certainly not the end of scaling. In the past, the reliability of a system was for the larger part guaranteed by the technology engineers. But very soon this will no longer be possible, and we are reaching a point where we, technology engineers, have to work together with system architecture experts to design reliable systems using ‘unreliable’ devices. In our research group we measure and try to understand reliability issues in scaled devices. In the 40nm technology, it is still possible to cope with the reliability issues of the devices and make a good system. But at 7nm, the unreliability of the devices risks to affect the whole system. And conventional design techniques can’t stop this from happening. New design paradigms are therefore urgently needed.”
Device aging becomes a very complex matter in scaled technologies. Groeseneken: “First of all, even with a fixed workload, the devices no longer degrade in a uniform way. Each individual device shows its own degradation level, so we have to start looking at the statistical distributions of degradation. And to make things worse, in a real system, the workload is not fixed. Just imagine a multimedia application in which the workload is dependent on the users’ instructions to the system. This workload dependence makes it very complex to predict the degradation of scaled devices in a system.”
Catthoor: “However, workload dependence doesn’t have to be negative. Ultimately, it even holds the key to the solution we are working on to make reliable systems with deeply scaled devices. Future systems will have distributed monitors that detect local errors in the system, an intelligent controller that gathers this information and decides what to do, and so-called knobs (actuators) that are regulated by the controller and fix the problem.”
Groeseneken: “You could compare it with our body where the nervous system detects where the pain or infection is situated, sends the results to the brain which is the control organ that steers cells to fix the problem or make the body react to avoid the cause of the pain. We can indeed learn a lot from the way evolution has made the most sophisticated system ever: our body and the human brain.”

The guard-band approach based on corner points becomes untenable for systems based on technology nodes beyond 14 nm. This article proposes a workload-dependent model.
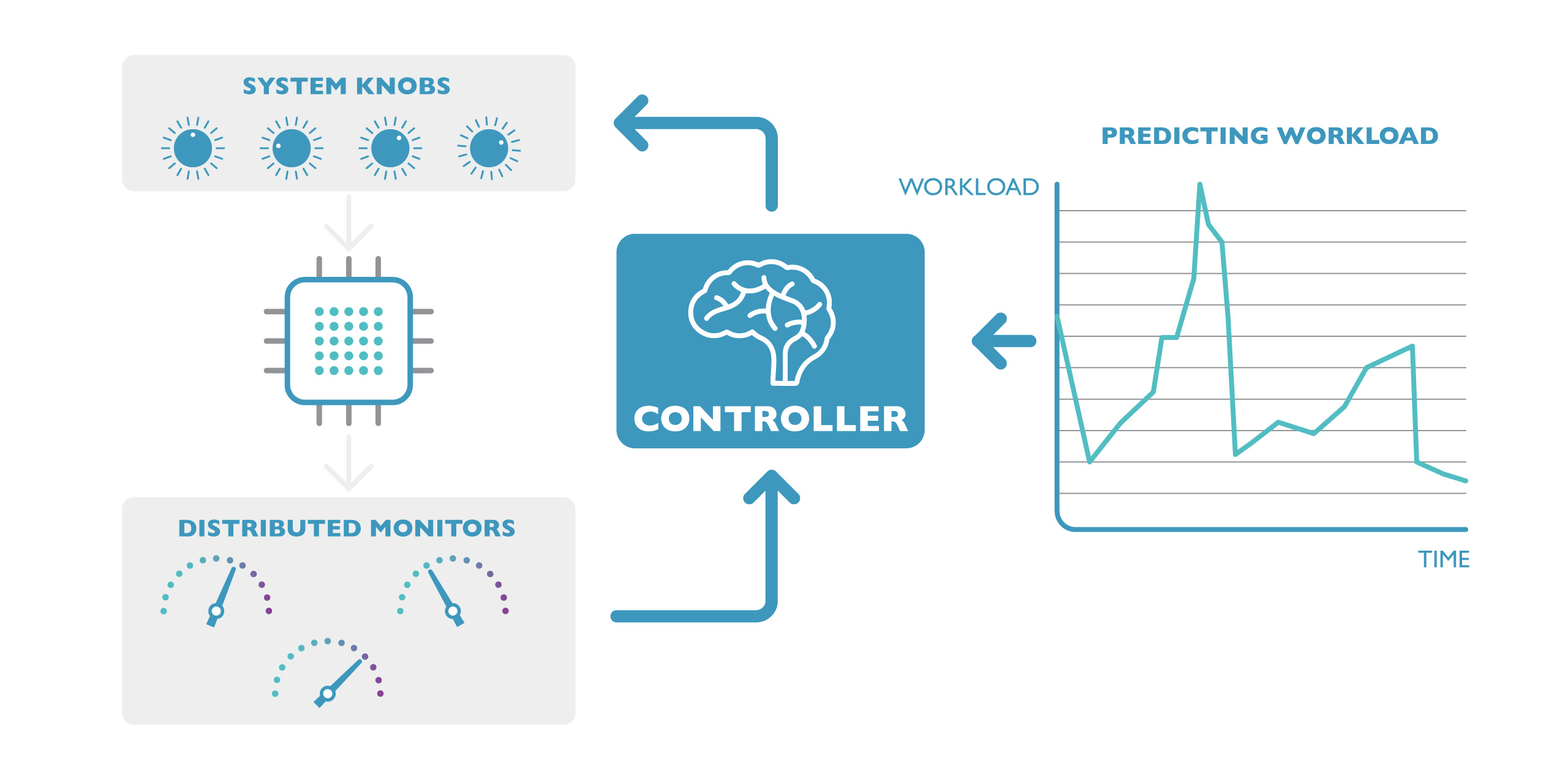
Future systems will include distributed monitors that detect local errors in the system, an intelligent controller that gathers this information and decides what to do, and knobs (actuators) that are regulated by the controller to fix the problem.
Monitoring the chip’s pain
The first requirement to make self-healing chips is to have a distributed monitor that can detect the chip’s pain very locally. Groeseneken: “There are various kinds of device variability that need to be monitored. First of all: the time-zero variability. This is the variation that exists in scaled devices, just after fabrication. Each transistor behaves slightly differently, even before they experience any kind of workload. This can be due to process variations during fabrication of the devices but is more and more dominated by so-called ‘intrinsic’ sources such as random dopant fluctuations or line edge roughness. This time-zero variability tends to become more important with deeply scaled devices. Secondly, there is a time-dependent variability: each device or transistor ages in a different way during the system’s operation. This can again be caused by differences in workload but also by intrinsic mechanisms such as random defect trapping in small devices. One has to make a distinction between functional reliability issues which affect the digital behavior of the device, and parametric reliability problems that affect the parameters of the device such as delay, power consumption, signal-to-noise ratio (SNR).”
The reliability of both the circuits and the whole system depends on the time-zero variability and the time-dependent variability of the devices. Catthoor: “And because these variations become more and more unpredictable, monitors are needed for both. A lot of research has been done on these monitors, especially in the academic world, and some are already in use today. For example, most chips today have functional monitors. In memories, where such error detection is rather easy to integrate and execute by doing a parity check. But even in arithmatic data paths, although less straightforward, functional monitors are developed and partly already in use today. Parametric monitors are less common for the moment. They are mainly used in highly-scaled high-performance applications.
An intelligent controller to heal the chip’s functional and parametric pain
The most important part of future self-healing chips is the controller. This chip’s brain will have to deal with both functional and parametric errors. Catthoor: “Both are linked to one another, but it’s important to fix the cause of the problem, not to focus on the consequences. If delay is the problem, then of course the functional behavior of the devices will be different too, but delay is the cause. On the other hand, if bit flipping is locally detected, than functional reliability mitigation has to be executed.”
Functional reliability mitigation is the healing of functional errors. Catthoor: “Functional reliability mitigation is used in scaled memories (e.g. 90nm). Just think of error-correcting code (ECC) memories in which bit flip problems are detected and corrected. Because in memories the focus is on density and scaling, the related problems and solutions typically first pop up here. With further scaling of memory cells, the ECC becomes more complex, more distributed and eventually the cost will become too high. New techniques are needed.”
Together with top university EPFL (École polytechnique fédérale de Laussane) imec is working on workload-dependent functional mitigation techniques for memories and data paths. Catthoor: “There are three levels at which mitigation can be integrated. Circuit-level mitigation is very generic and can thus be used for every architecture style and application, but it implies an overhead in area and energy. The other extreme is mitigation at application level. This one is very specific but has to be redeveloped for every new application. Most companies don’t want to do this because of the high implied system design cost. In between, there is the mitigation at system-architecture level. This is not too specific and doesn’t create too much overhead. Imec, together with its academic partners, focuses on architecture-level mitigation and circuit-level mitigation (the latter only when fabrication cost can be kept low).
Also for parametric reliability issues, we are developing workload-dependent techniques. Again, our academic partners play a key role. Together with TU Delft we develop circuit-level mitigation techniques for SRAMs. And with NTU Athens we work on architecture-level mitigation techniques. Together we are developing a partly proactive system scenario-based controller. This controller prevents delay errors from propagating and causing damage at the system level. At the device level you can’t prevent these errors, but at the system level you can prevent them from doing harm. The collaboration with research teams like the one of Guido Groeseneken is very important because they provide us with the data and the models for the failure mechanisms that have to be used in the mitigation techniques.” Groeseneken: “The big advantage for imec of doing this work is that we have all expertise needed under one roof, which puts us in a quite unique position to do this research”.
A fortuneteller for self-healing chips
The ultimate goal of imec and its academic partners is to develop a fully proactive parametric reliability mitigation technique with distributed monitors, a control system and actuators, fully preventing the consequence of delay faults and potentially also of functional faults. Catthoor: “The secret to the solution lies in the workload variation of the system. Based on a deterministic predictor of the future, you determine future slack and use this to compensate for the delay error at peak load. Based on this info on the future, you change the scheduling order and the assignment of operations.” Groeseneken: “Only with this self-healing approach (the fully proactive approach), we will be able to scale down to 5nm technologies. Actually, I believe that this approach is also present in our human body. Our brain and body are not designed (by evolution) to constantly cope with peak loads, but they keep in mind that in the future better times will come and use this slack to cope with current peak loads.”
Catthoor: “Workload-dependent modeling is essential to making reliable systems with scaled and unreliable devices. Imec brings together the knowledge on monitors, controllers and knobs that is being developed at the universities. We combine this with the knowledge from our technology people to work out simulations and develop a fully proactive mitigation approach for future chips. The interactions we have with industrial partners allow us to develop an industry-relevant technique. I expect that by 2025, the industry will make true self-healing chips, and consumers will use truly reliable systems and applications. As in so many fields, the solution lies in collaboration. In bringing the expertise of technologists and system architects together, and in combining the essential contributions of academic groups and research centers that bring the early concepts in reach of the industry and society.”

Self-healing chips could use the workload variation of the system for their benefit. Based on a deterministic predictor of the future, future slack is determined and used to compensate for the delay error and mitigate at peak load.
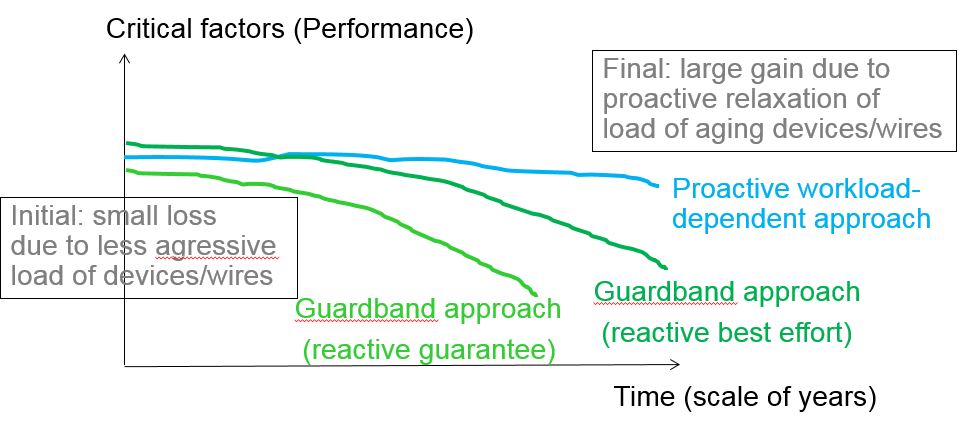
The proactive reliability mitigation approach based on the workload dependence implies a small initial loss in performance at time zero, but a large gain in system reliability over the years.












